Method
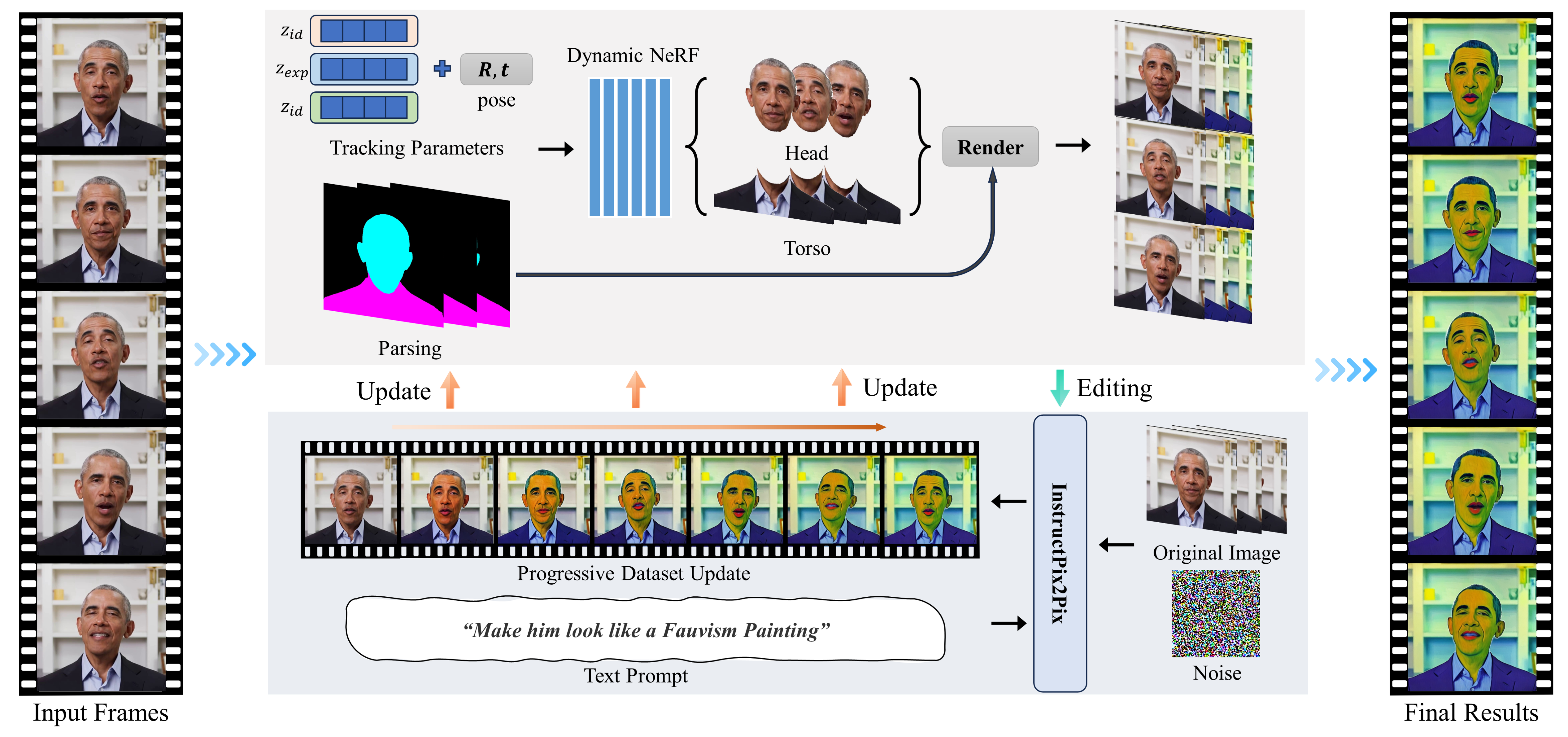
We train two dynamic neural radiance fields to reconstruct the head and torso region separately based on the tracking coefficient and pose. Once the NeRF model is constructed, we use Instruct-Pix2Pix to generate edited results based on the instruction and progressively update the sequence datasets and NeRF model. In the end, through the utilization of the NeRF-based portrait representation, we are able to produce an editing sequence that maintains temporary coherence and 3D consistency.