PortraitGen lifts 2D portrait video into 4D Gaussian field.
It achieves multimodal portrait editing in just 30 minutes ⏰.
The edited 3D portrait could also be rendered at 100 FPS ⚡.
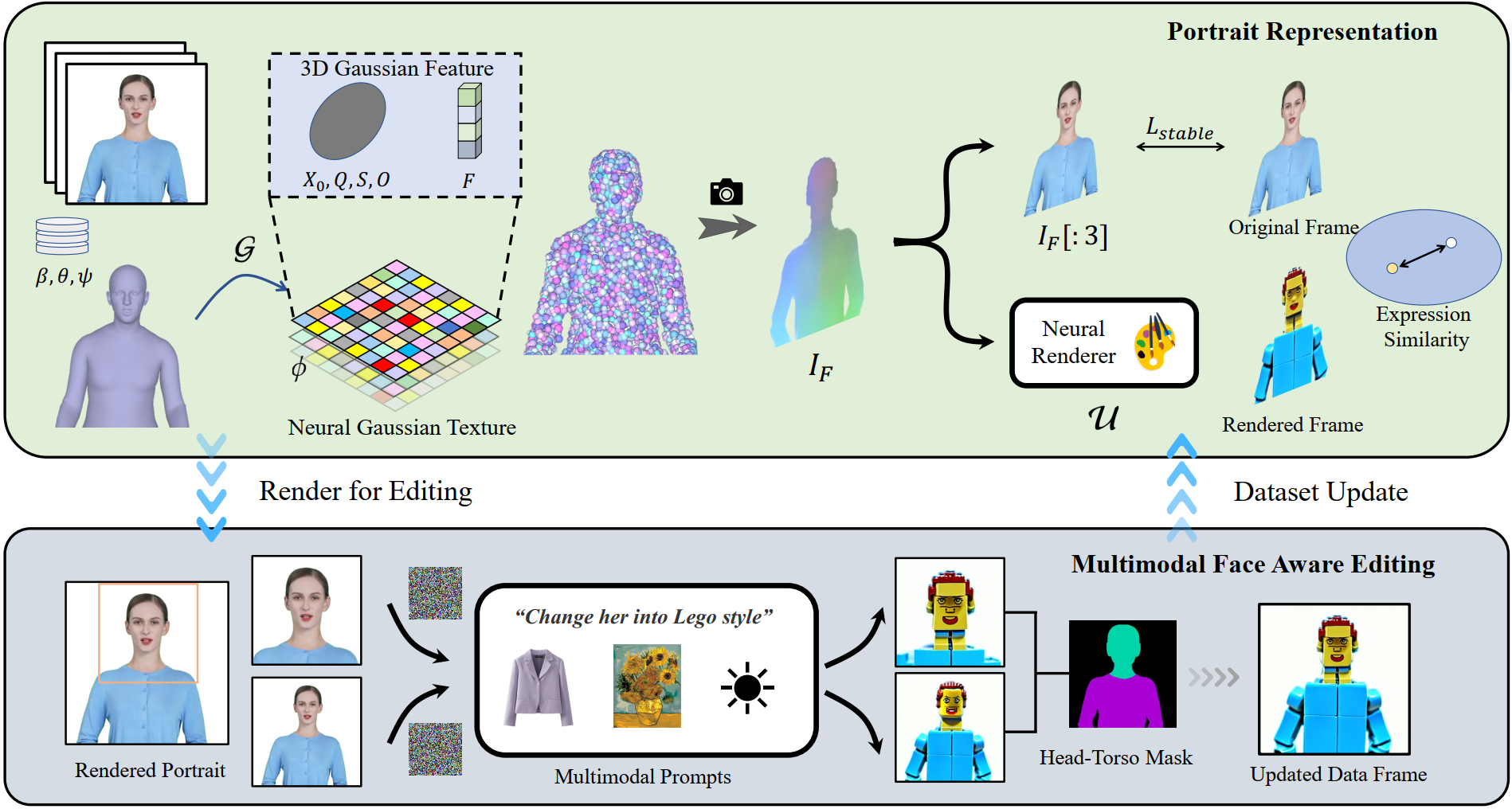
We first track the SMPL-X coefficients of the given monocular video, and then use a Neural Gaussian Texture mechanism to get a 3D Gaussian feature field. These neural Gaussians are further splatted to render portrait images. An iterative dataset update strategy is applied for portrait editing, and a Multimodal Face Aware Editing module is proposed to enhance expression quality and preserve personalized facial structures.