Method Overview
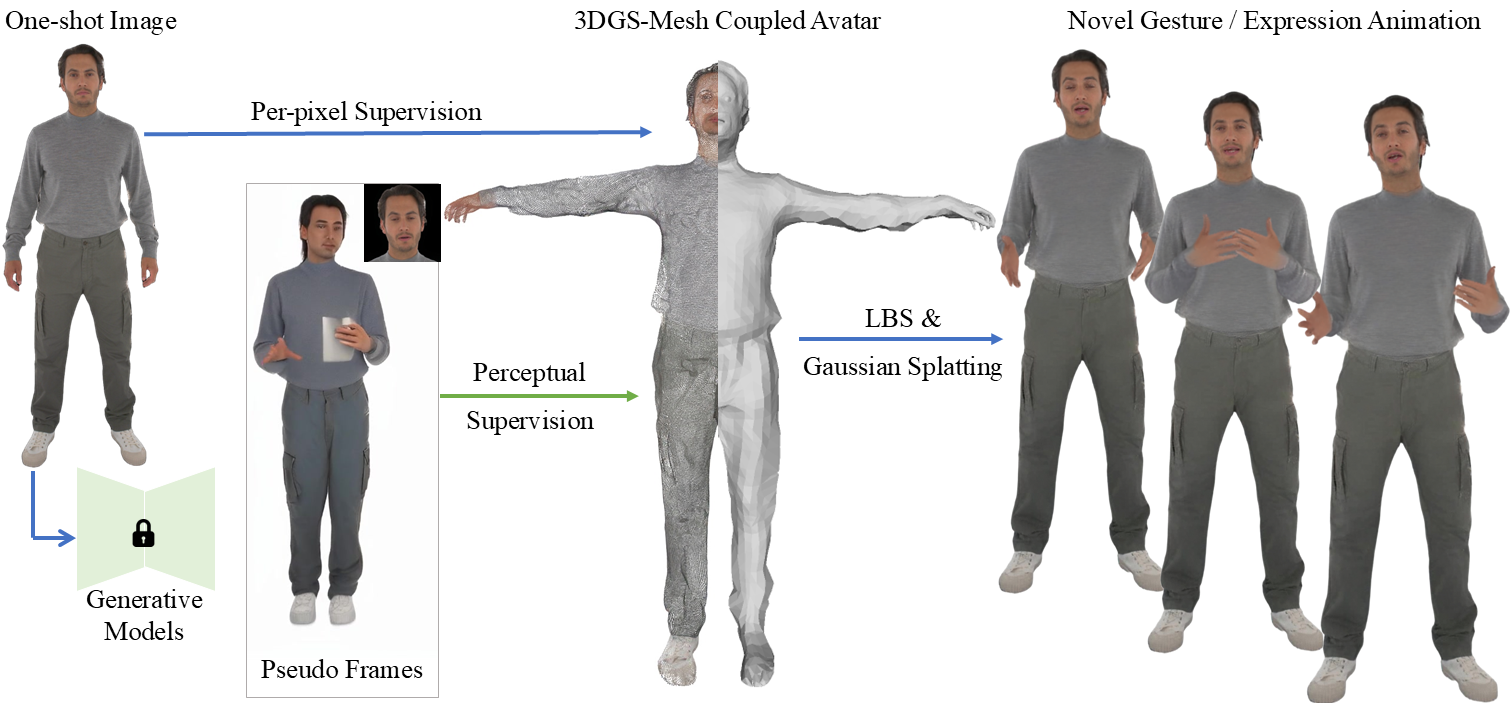
Our method constructs an expressive whole-body talking avatar from a single image. We begin by generating pseudo body and head frames using pre-trained generative models, driven by a collected video dataset with diverse poses. Per-pixel supervision on the input image, perceptual supervision on imperfect pseudo labels, and mesh-related constraints are then applied to guide the 3DGS-mesh coupled avatar representation, ensuring realistic and expressive avatar reconstruction and animation.