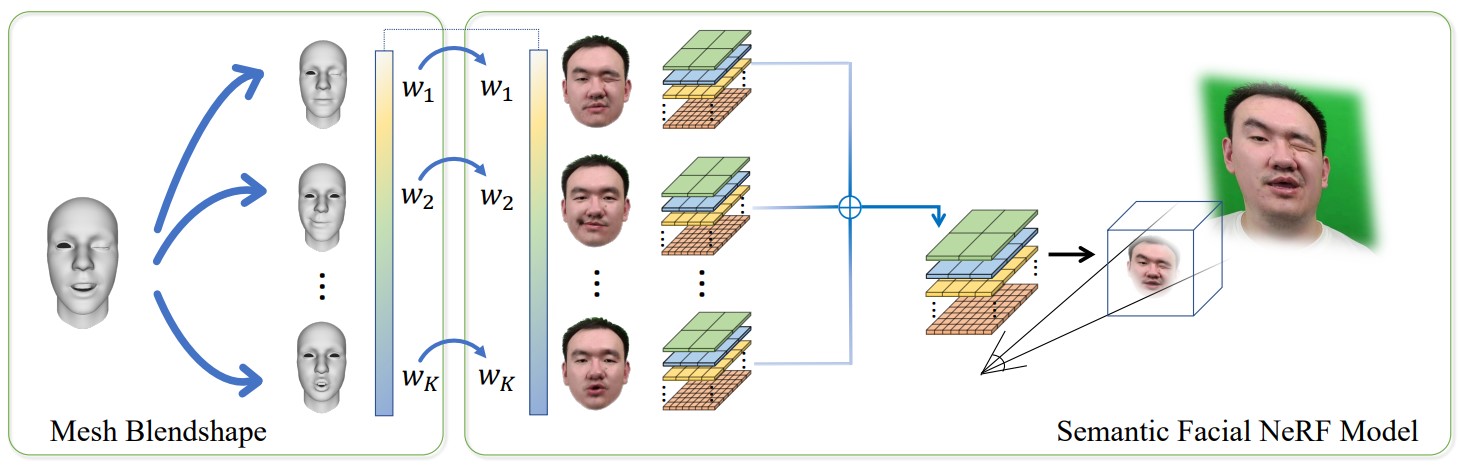
We present a novel semantic model for human head defined with neural radiance field. The 3D-consistent head model consists of a set of disentangled and interpretable bases, and can be driven by low-dimensional expression coefficients. Thanks to the powerful representation ability of neural radiance field, the constructed model can represent complex facial attributes including hair and wearings, which can not be represented by traditional mesh blendshape. To construct the personalized semantic facial model, we propose to define the bases as several multi-level voxel fields. With a short monocular RGB video as input, our method can construct the subject's semantic facial NeRF model in only ten to twenty minutes and can render a photo-realistic human head image in tens of milliseconds with a given expression coefficient and view direction. With this novel representation, we apply it to many tasks like facial retargeting and expression editing. Experimental results demonstrate its strong representation ability and training/inference speed.
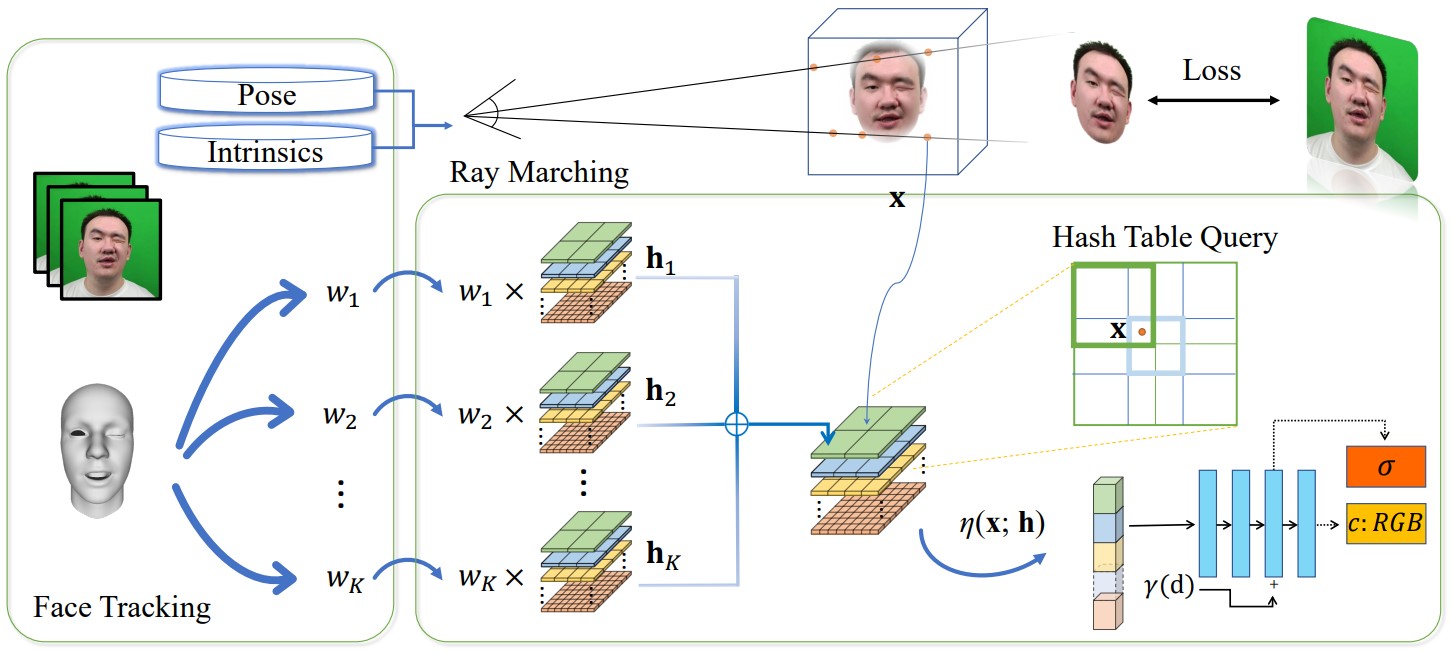
We track the RGB sequence and get expression coefficients, poses, and intrinsics. Then we use the tracked expression coefficients to combine multiple multi-level hash tables to get a hash table corresponding to a specific expression. Then the sampled point is queried in the hash table to get voxel features, we use an MLP to interpret the voxel features as RGB and density. We fix the expression coefficients and optimize the hash tables and MLP to get our head model.
Our model can be easily used for facial reenactment. We track the source subjects' video and get poses, camera intrinsics, and expression coefficients. The poses and intrinsics are utilized to cast rays, and we further use expression coefficients to combine targets' bases. Then the sampled point is queried in the final hash table and interpreted by MLP to predict RGB and density. Compared with other methods, our model demonstrates more personalized facial details and synthesizes a more reasonable human head conditioned on expression coefficients both in self-reenactment and cross-identity reenactment.
Our model could converge to a reasonable result in 20 minutes. The implicit blendshape architecture plays an important role in the learning process. Compared with a baseline model concatenating multi-level hash features with expression coefficients, our model could learn a dynamic head scene much faster.
Thanks to the 3D consistency of NeRF, our model could also disentangle the camera parameters. Thus we can freely adjust the camera parameters of our model to generate novel view synthesis results. We first use a set of expression coefficients from the testset to combine bases to get the corresponding radiance field. Then the rendered images with different rendering views are generated by the volume rendering.
If you find our paper useful for your work please cite:
@article{Gao2022nerfblendshape,
author = {Xuan Gao and Chenglai Zhong and Jun Xiang and Yang Hong and Yudong Guo and Juyong Zhang},
title = {Reconstructing Personalized Semantic Facial NeRF Models From Monocular Video},
journal = {ACM Transactions on Graphics (Proceedings of SIGGRAPH Asia)},
volume = {41},
number = {6},
year = {2022},
doi = {10.1145/3550454.3555501} }