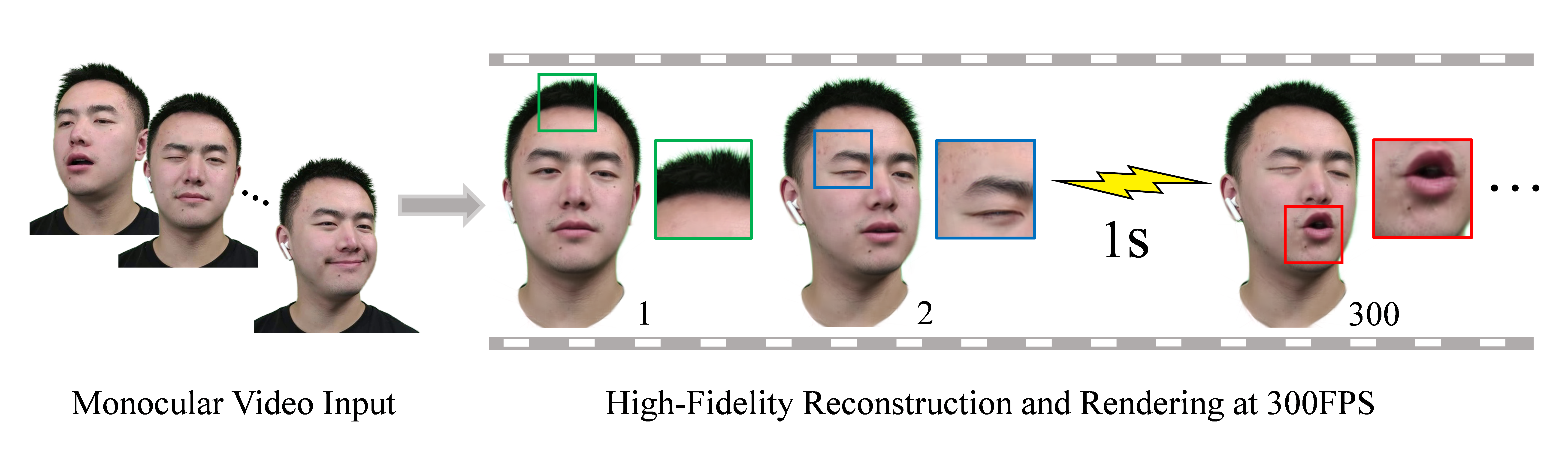
We propose FlashAvatar, a novel and lightweight 3D animatable avatar representation that could reconstruct a digital avatar from a short monocular video sequence in minutes and render high-fidelity photo-realistic images at 300FPS on a consumer-grade GPU. To achieve this, we maintain a uniform 3D Gaussian field embedded in the surface of a parametric face model and learn extra spatial offset to model non-surface regions and subtle facial details. While full use of geometric priors can capture high-frequency facial details and preserve exaggerated expressions, proper initialization can help reduce the number of Gaussians, thus enabling super-fast rendering speed. Extensive experimental results demonstrate that FlashAvatar outperforms existing works regarding visual quality and personalized details and is almost an order of magnitude faster in rendering speed.
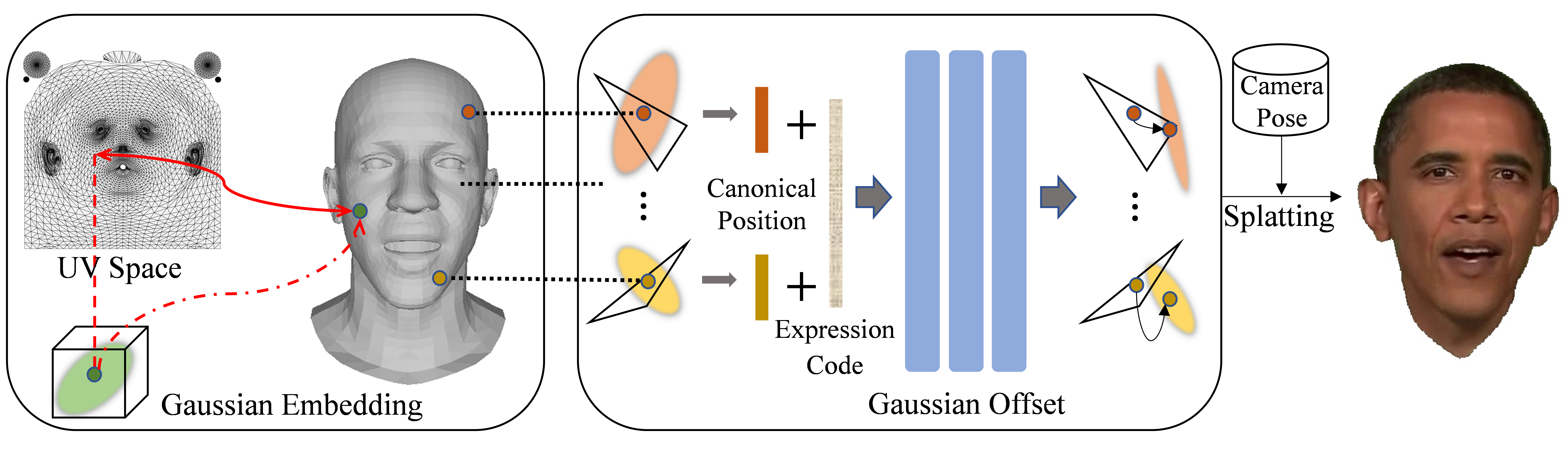
We initially maintain the 3D Gaussian field in 2D UV space and embed them into dynamic FLAME mesh surfaces through mesh rasterization. For every surface-embedded 3D Gaussian, the offset network takes tracked expression code and the corresponding position of the Gaussian center on canonical mesh as input, outputs the spatial offset, including position, rotation, and scaling deformation. The deformed Gaussians are then splatted to render the image with a given pose.
We compare our method with three representative works. As we can see, FlashAvatar produces photo-realistic images most consistent with the ground truth. We recover almost all fine facial details, thin structures, and subtle expressions with 3D Gaussians in 10K level. As both mesh dynamics and later Gaussian deformation condition on tracked expression code disentangled from identity space, we could conduct facial reenactment task at super-fast rendering speed with no difficulty. Note that for PointAvatar, the full training requires 80GB A100 GPU, but we train it on 32GB V100 and use fewer points and earlier checkpoints exactly following the author's suggestions. All other experiments were done on 24GB Nvidia RTX 3090.
We achieve a remarkable rendering speed over 300FPS. Meanwhile, we demonstrate that our training process is super efficient as well. We are able to recover the coarse appearance of head in several seconds and reconstruct the photo-realistic avatar with fine hair strands and textures within a couple of minutes. We conduct both training and inference on a single Nvidia RTX 3090.
The basic representation of 3D head avatars in our method is pure non-neural 3D Gaussians, so we can freely adjust the global camera pose to generate target results with any desired rendering view.
In this paper, we have proposed FlashAvatar, which tightly combines a non-neural Gaussian-based radiance field with an explicit parametric face model and takes full advantage of their respective strengths. As a result, it can reconstruct a digital avatar from a monocular video in minutes and animate it at 300FPS while achieving photo-realistic rendering with full personalized details. Its efficiency, robustness, and representation ability have also been verified by extensive experimental results.
If you find our paper useful for your work please cite:
@inproceedings{xiang2024flashavatar,
author = {Jun Xiang and Xuan Gao and Yudong Guo and Juyong Zhang},
title = {FlashAvatar: High-fidelity Head Avatar with Efficient Gaussian Embedding},
booktitle = {The IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2024},
}