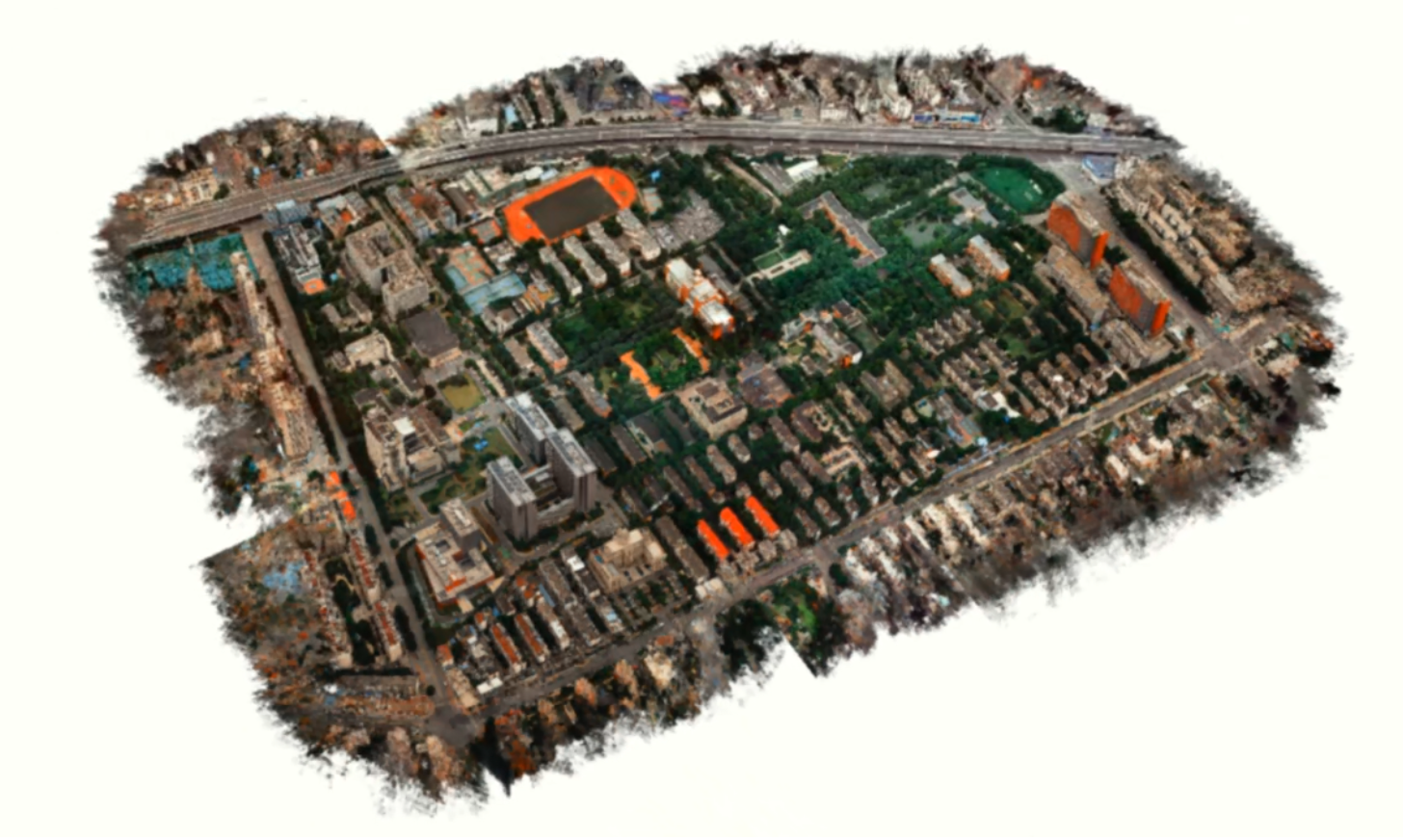
We present City-on-Web, which to our knowledge is the first system that enables real-time neural rendering of large-scale scenes over web using laptop GPUs. The result is tested on the NVIDIA RTX 3060 Laptop GPU with 1920x1080 resolution.


Abstract
Existing neural radiance field-based methods can achieve real-time rendering of small scenes on the web platform. However, extending these methods to large-scale scenes still poses significant challenges due to limited resources in computation, memory, and bandwidth. In this paper, we propose City-on-Web, the with dynamic loading/unloading of resources to significantly reduce memory demands. Our system achieves real-time rendering of large-scale scenes at approximately 32FPS with RTX 3060 GPU on the web and maintains rendfirst method for real-time rendering of large-scale scenes on the web. We propose a block-based volume rendering method to guarantee 3D consistency and correct occlusion between blocks, and introduce a Level-of-Detail strategy combinedering quality comparable to the current state-of-the-art novel view synthesis methods.
Motivation
Challenge
- Merf struggles to scale to larger scenes due to limited representational capacity.
- Web-based rendering has constraints on the number and resolution of texture units, preventing loading of resources for all blocks into one shader.
- Aggregating samples of different blocks for volume rendering becomes difficult due to resource-independent nature of multi shaders.
- Substantial video memory usage due to the necessity of rendering rich-detail large-scale scenes.
- Merf struggles to scale to larger scenes due to limited representational capacity.
- Web-based rendering has constraints on the number and resolution of texture units, preventing loading of resources for all blocks into one shader.
- Aggregating samples of different blocks for volume rendering becomes difficult due to resource-independent nature of multi shaders.
- Substantial video memory usage due to the necessity of rendering rich-detail large-scale scenes.
Solution
- Implement a block-based strategy, dividing the scene into manageable blocks, each represented by a merf model.
- Utilize multiple shaders to load resources from different blocks
- Introduce a block-based volume rendering method ensuring 3D consistency and correct occlusion within this resource-independent environment.
- Utilizing multiple levels-of-detail and dynamic loading strategy based on camera position to significantly reduce memory demands.
- Implement a block-based strategy, dividing the scene into manageable blocks, each represented by a merf model.
- Utilize multiple shaders to load resources from different blocks
- Introduce a block-based volume rendering method ensuring 3D consistency and correct occlusion within this resource-independent environment.
- Utilizing multiple levels-of-detail and dynamic loading strategy based on camera position to significantly reduce memory demands.
Training Pipeline
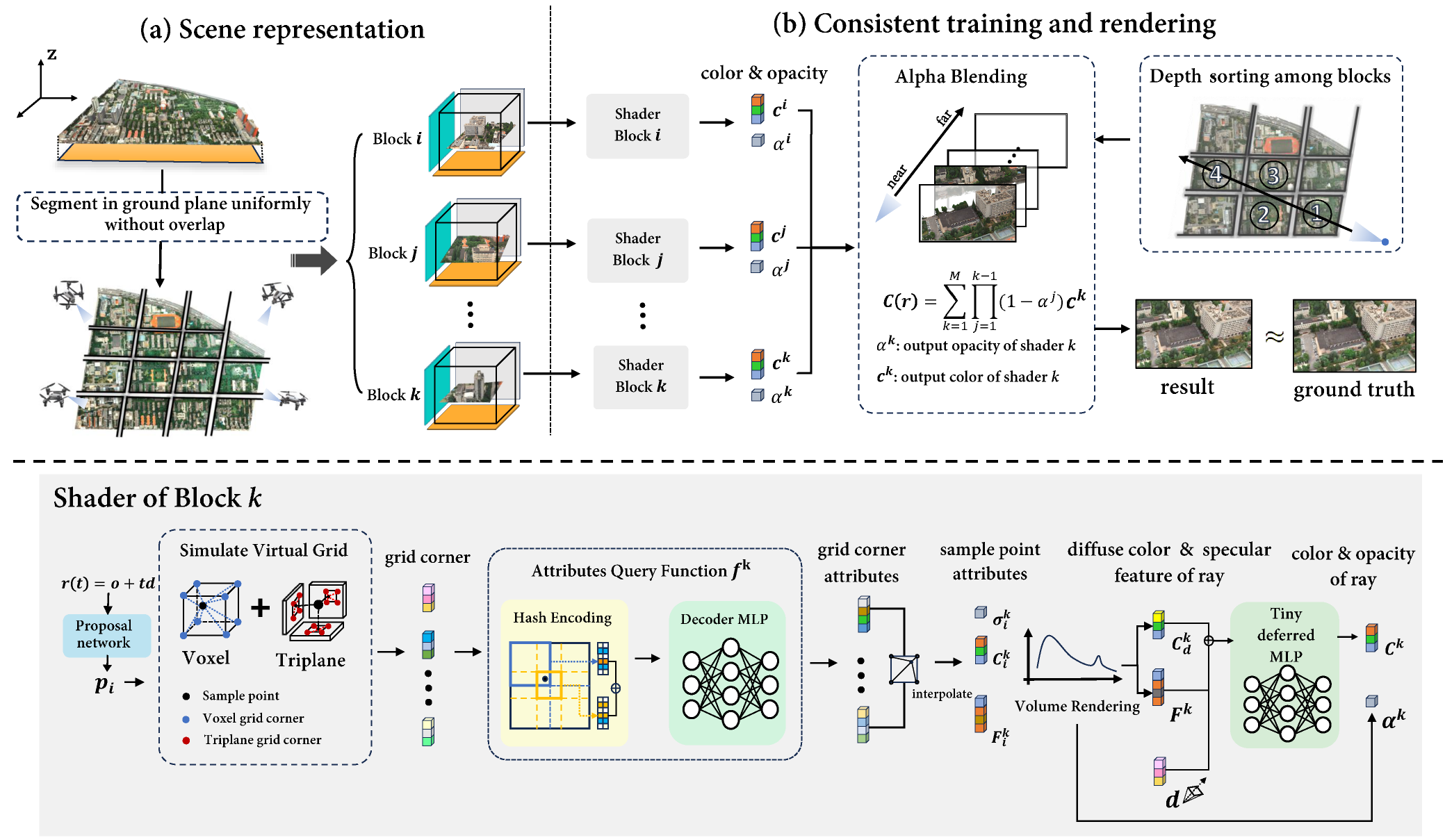
We first divide the entire scene into different blocks without overlap according to the ground plane. For the block that the ray passes through, the corresponding shader renders the color and opacity of each block. We depth sort the blocks that ray traversed, and then render the final result through alpha blending that maintains 3D consistency.
Resource-independent Volume Rendering
To facilitate volume rendering in the resource-independent environment with multiple shaders, the blocks are sorted by their distance from the camera. We then blend the rendering results according to the sequence. Using our derived alpha blending method, the rendering results can blend correctly. This method is occlusion-aware and maintains 3D consistency.
- Difference from MERF: Merf conducts a global integration followed by deferred rendering, while our method performs integration by parts.
- Difference from Block-NeRF: Block-NeRF conducts sampling and volumetric rendering solely within a single block.
- Difference from Mega-NeRF: Mega-NeRF do volume rendering together, which often struggle with rendering in resource-independent environment.
LOD Generation
We generate additional LODs from the most detailed level obtained in the training stage. For every four block models, we downsample the resolution of each submodel’s virtual grid and then retrain a shared deferred MLP. Initially, we freeze the merf models to ensure the appearance remains consistent with finer LOD result. Afterward, we train the merf models and the shared deferred MLP together to refine the scene further.
Rendering
In the rendering phase, the choice of different LODs and blocks for rendering is dynamically determined based on the camera's position and the view frustum. These selected blocks are then processed in their respective shaders to produce the color and opacity. And We leverage our block-based volume rendering strategy to ensure three-dimensional consistency and correct occlusion.
Comparison with SOTA Method
Our method excels in recovering finer details and achieves a higher quality of reconstruction across diverse scales and environments.

LOD Result

BibTeX
If you find our paper useful for your work please cite:
@inproceedings{Song2024City,
author = {Kaiwen Song and Xiaoyi Zeng and Chenqu Ren and Juyong Zhang},
title = {City-on-Web: Real-time Neural Rendering of Large-scale Scenes on the Web},
booktitle = {European Conference on Computer Vision (ECCV)},
year = {2024}
}